Find web elements in Selenium C# and how to identify the correct web element or XPath to perform automation with selenium C#. these elements will be required to perform the operation like, Click, Type Text, Get Text, etc in the automation script.
What are Web Elements in Selenium C#
All the UI components used in the webpage are web elements. In order to interact with the web elements first, we need to locate them on the webpage.
For locating them we have to use two methods that are “FindElement()” and “FindElements()”, these two methods will take the “By” class as an argument.
By class contain a lot of static methods which help us to identify an element on the webpage.
If we go to visual studio and there we go to the class definition of By class so we can see here it contains a lot of static methods that will help us to identify an element on the webpage.
Type of Methods to find web elements in Selenium C#
- By.Id(): It is used to locate the element based on the value of the id attribute.
- By.ClassName(): It is used to identify an element of the webpage based on the value of the class attribute.
- By.LinkText() & By.PartialLinkText(): they will identify an element based on the hyperlink which is present on the webpage. The difference between both of them is that in By.LinkText() we need to supply the exact link text but in By.PartialLinkText() we can supply parts or part of the link text.
- By.CssSelector(): It will identify the element based on the CssSelector.
- By.Name(): It will identify the element based on the value of the Name attribute.
- By.TagName(): It will identify the web element based on the tag name. Tag name can be <input>, <div>, <form> and so on.
FindElement() Method in Selenium C#
In my visual studio inside the test script, I am creating one more folder let me call it as WebElement now inside this WebElement directory I am adding a class called TestWebElement and making it public.
[TestClass]
public class TestWebElement
{
[TestMethod]
public void GetElement()
{
NavigationHelper.NavigateToUrl(ObjectRepository.Config.GetWebsite());
try
{
ObjectRepository.Driver.FindElement(By.TagName("input")); ObjectRepository.Driver.FindElement(By.ClassName("btn")); ObjectRepository.Driver.FindElement(By.CssSelector("#Find")); ObjectRepository.Driver.FindElement(By.LinkText("File a Bug")); ObjectRepository.Driver.FindElement(By.PartialLinkText("File"));
ObjectRepository.Driver.FindElement(By.Name("quick search")); ObjectRepository.Driver.FindElement(By.Id("Find_bottom")); ObjectRepository.Driver.FindElement(By.XPath("//input[@id='find']")); ObjectRepository.Driver.FindElement(By.XPath("//input[@id='findl']"));
}
catch(NoSuchElementException e)
{
Console.WriteLine(e);
}
}
}
Inside this class i am creating one public method, public void GetElement() and using the attribute [TestClass] and [TestMethod] with it. In order to use the method FindElement().
I am going to take the help of driver property now here we will write ObjectRepository.Driver.FindElement so as we can see here it is going to take the element as “By”.
As I told you all the methods are static so we need to use the class name in order to access them. So here I am opening my Chrome and inside this, I am opening the Bugzilla webpage.
For example, I want to inspect an element that is a search box so here I will use the $x for the Xpath, $x("//input") and let’s say this is the Xpath.
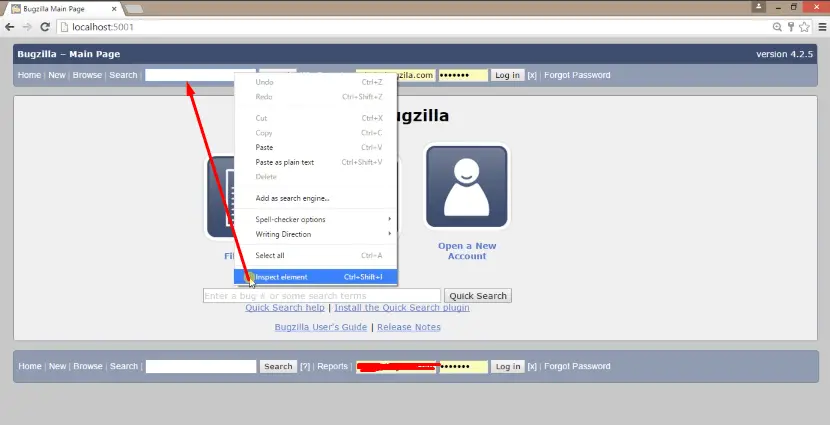
As you can see in the below image there are a lot of elements with the tag name as “input”, so in my script, I have supplied the TagName as “input” (By.TagName(“input”));.
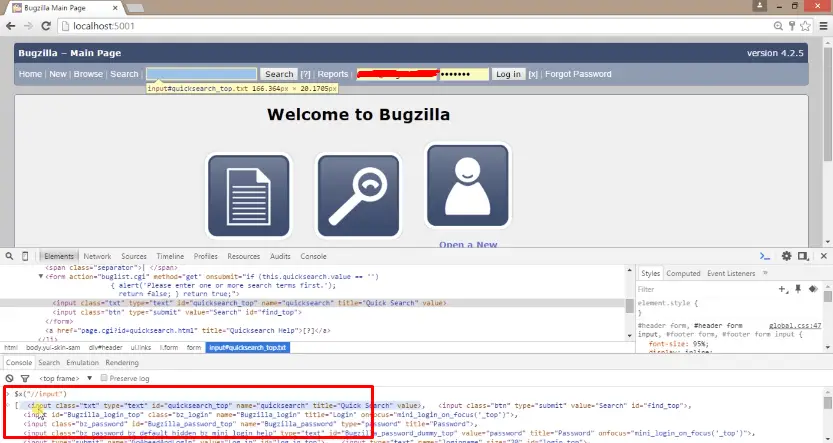
For ClassName this particular attribute takes the value of the class attribute. I want to inspect the search button element, as we can see here it has the value of the class attribute as class="btn". So I have supplied the ClassName as (By.ClassName("btn")); .
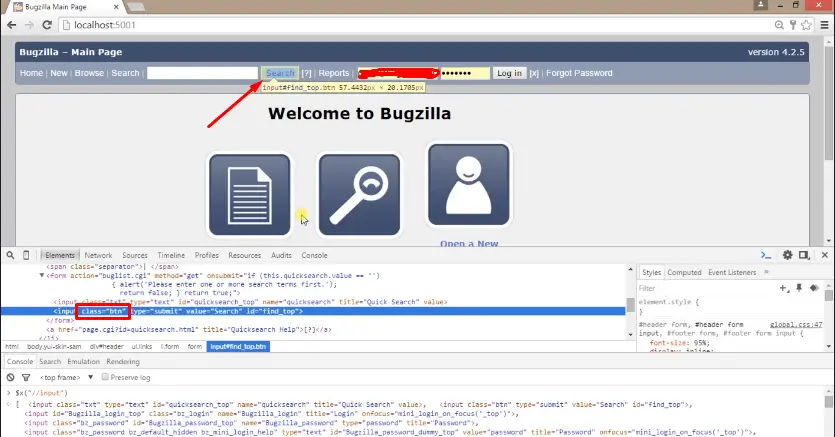
After that, for CssSelector we need to use $$ and a shorthand operator for id is #. So I want to inspect an element in the Quick search button the value of the id attribute of this element is “find. That’s why i have supplied (By.CssSelector("#Find")); .
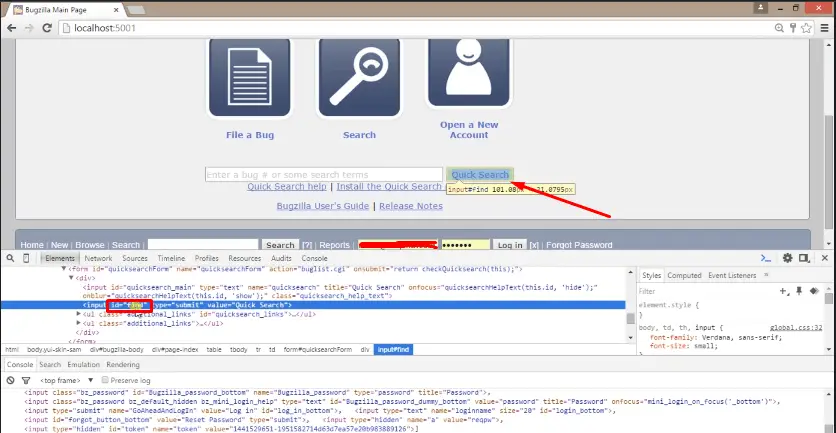
For LinkText I want to inspect the element is “File a Bug” hyperlink.
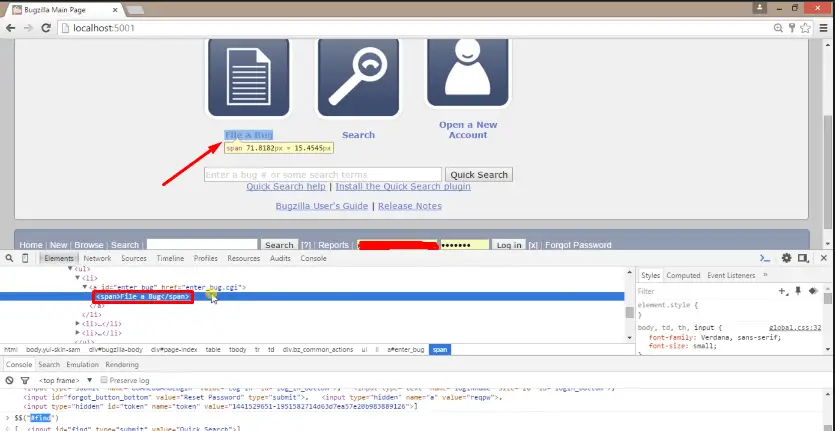
So I have supplied here (By.LinkText(“File a Bug”)); similarly for PartialLinkText again I inspect the same hyperlink for this I have supplied only a part of the linked text as (By.PartialLinkText(“File”));.
Similarly for other elements like I want to inspect the Quick search Textbox element and its value for name attribute is “quick search”.
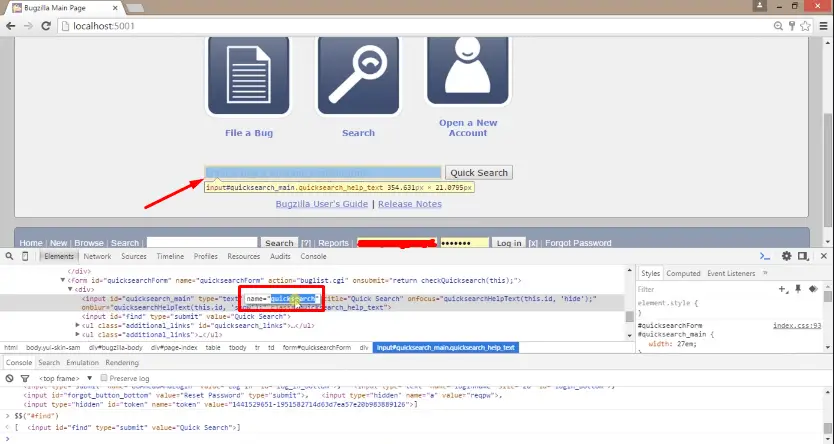
For inspecting the search button element its value for the id attribute is “find_bottom” and for inspecting the Quick search button its Xpath is ("//input[@id="find"]").
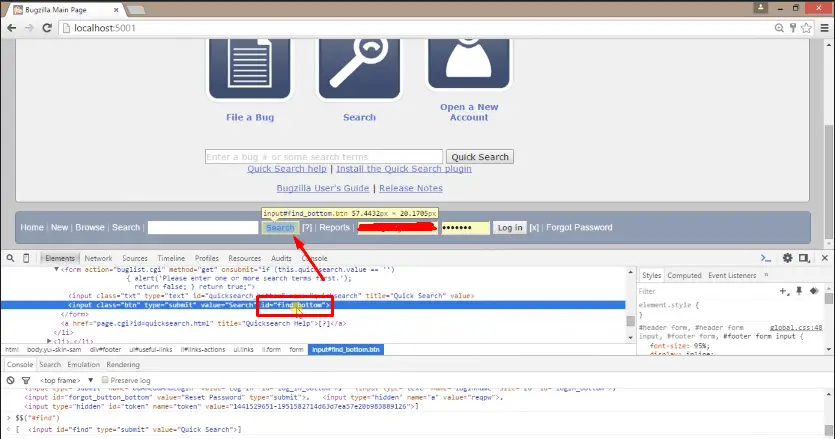
I have supplied all the values of attributes for their corresponding elements.
Now let us suppose the attribute which we have supplied is not present on the webpage which means the Xpath or CssSelector we have supplied is not identifying any element of the webpage in this case this particular method will throw NoSuchElementException.
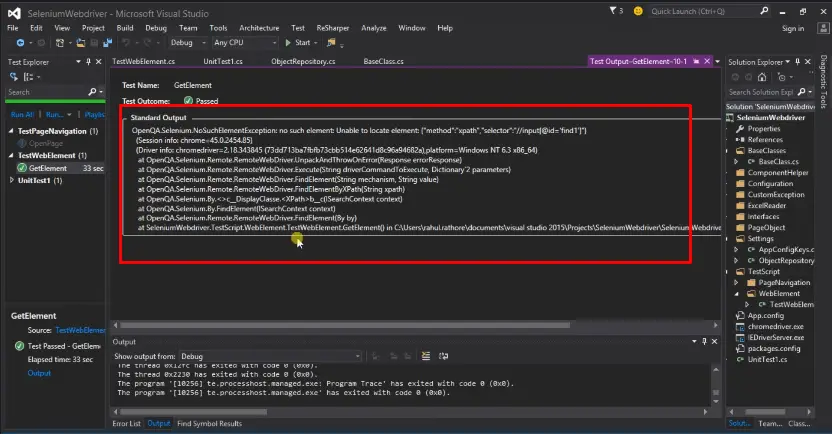
For that, I am using a try-catch block. Move all the statements in the try block. And catch block will handle (NoSuchElementException e). In this block write Console.WriteLine(e); and in try block also I have supplied Xpath of one element which is not present on the webpage it’s just for testing purposes.
So I have added a statement ObjectRepository.Driver.FindElement(By.XPath("//input[@id='findl']")); here I have written the value of id as “findl” that has no corresponding element.
Also, we are using NavigationHelper to open the webpage. NavigationHelper.NavigateToUrl(ObjectRepository.Config.GetWebsite()); and I am putting the debug point on this statement ObjectRepository.Driver.FindElement(By.TagName("input")); now we have built our solution and run the project in debug mode.
So, first of all, it has launched the Chrome browser then it has opened the Bugzilla webpage in it, when we are doing step over it is selecting elements related to the TagName, ClassName, CssSelector, and so on.
But when we have reached to the last statement of Xpath there is no such element present on the webpage related to it, so this is throwing an exception as you can see in the below image.
FindElements() Method in Selenium C#
Now moving on to the next method that is FindElements(). The difference between FindElement() and FindElements() is that the First method will return us only the single web element, but the FindElements() method will going to return us the list of web elements. So what is a list, we can consider a list as a collection of data.
For example- let us consider a list of tasks I have Task1, Task2, and Task3. This kind of representation can be done with the help of the list in the code.
Example to Understand the List Concept
So in order to create a list, we will use IList which is an interface. IList<> this represents the generic type means here we need to supply the data type of the data which are the list is going to contain. So here I am specifying <string> that means the list will have only the string data type of data.
IList<string> list= new List<string>();
list.Add("Task1");
list.Add("Task2");
list.Add("Task3");
Console.WriteLine("size:(0)",list.Count);
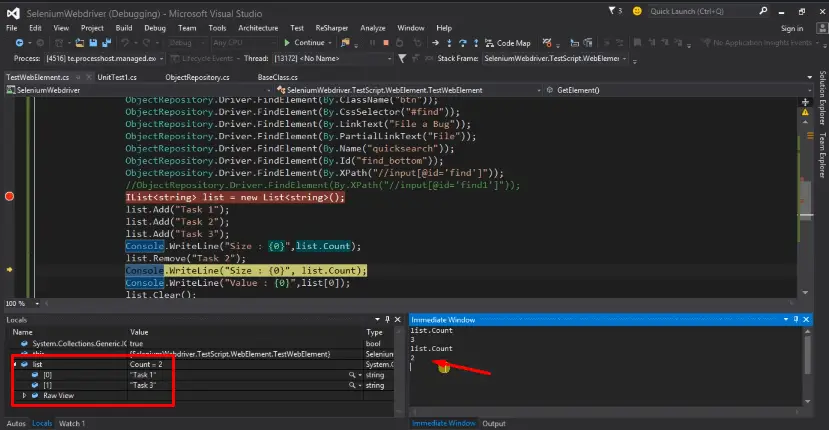
list.Remove("Task2");
Console.WriteLine("size:(0)",list.Count);
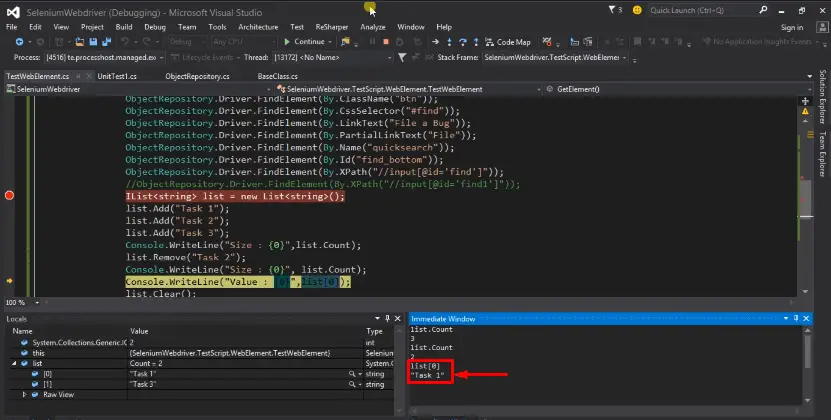
Console.WriteLine("value:(0)",list[0]);
list.Clear();
Console.WriteLine("size:(0)",list.Count);
Now in order to add the element inside the list, we are using list.Add() . Add is a method as you can see here it expects the string item because we have specified the data type of the list that it should be only contain string data. We are adding Task1, Task2 & Task3 to this list.
We have a method called list.Count which gives us the size of the list. If we want to remove any item from the list there is a method called list.Remove(“”) and in the bracket, we have to specify the item whichever we want to remove.
Again we are checking for size then suppose if we want to retrieve any value for that we are writing Console.WriteLine(“value:(0)”,list[0]); and in [] square brackets here we need to supply the index value so i am using [0] to get the first element.
And then we have a method called list.Clear(); which is going to remove all the elements present inside the list and also the size count will become 0 (zero).
Output:
We are putting the breakpoint here IList<string> list= new List<string>(); now we are running the script in debug mode so it is creating the list first. Then adding the tasks as you can see here if we expand the list it has all the items.
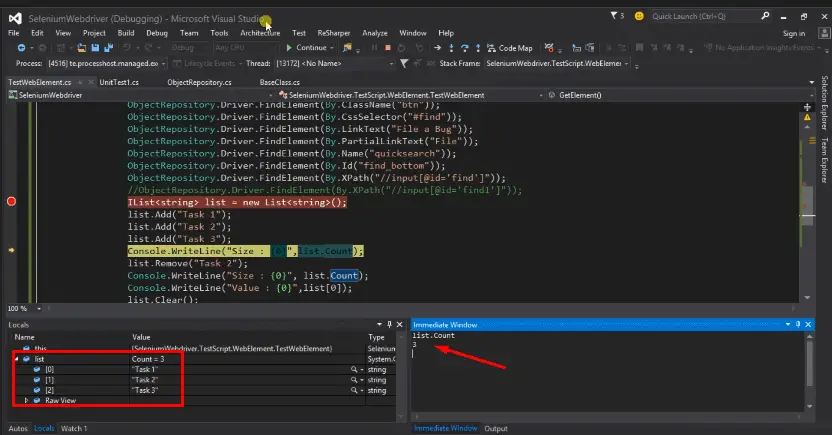
It is giving me the size in the immediate window as 3, then it’s removing task2 and now we can see there are only two items are left Task1 and Task3 now count is reducing to 2.
After that, it is giving us the item which is present on the particular index so on the [0] th index there is Task1.
Then we are calling the Clear() method it is removing all the items from the list.
![]()
Therefore it is making the size as 0 means there is no items present in the list. That’s all for the list concept.
Using FindElements() method:
Now as we have discussed that FindElements() is going to return us the list of web elements, in other words it will return the read only collection. That means we cannot modify that particular list.
From the name that is ReadOnlyCollection we can understand that it can be only used for the reading purpose.
For example- if we type this Xpath $$(“//input”) so using this Xpath as we can see here there are lot of web elements present inside the web page related to it. So now we will call the method FindElements() here.
[TestClass]
public class TestWebElement
{
[TestMethod]
public void GetElement()
{ NavigationHelper.NavigateToUrl(ObjectRepository.Config.GetWebsite());
try
{
ReadOnlyCollection<IWebElement> col= ObjectRepository.Driver.FindElements(By.TagName("input"));
Console.WriteLine("size:(0)",col.Count);
Console.WriteLine("size:(0)",col.ElementAt(0));
}
catch(NoSuchElementException e)
{
Console.WriteLine(e);
}
}
}
As we can see here the return type of this method is ReadOnlyCollection and the collection is of type web element so that is why we are creating here the collection type <IWebElement>, IWebElement is an interface which contains some certain methods by which we can deal with the web elements.
Basically here we want that it will list us all the web elements of that web page who has tag name as “input”. And also we are going to return the size of the list from Console.WriteLine(“size:(0)”,col.Count); statement and then again for retrieve the first element of the list for that Console.WriteLine(“size:(0)”,col.ElementAt(0)); in () bracket we have to specify the index value. Now we will put debug point on the ReadOnlyCollection statement then run the script in debug mode.
First it will return us the list of all the web elements which has a TagName as “input”. If we look into the image there are total 22 web elements related to this TagName. We can see all of them by expanding the list.
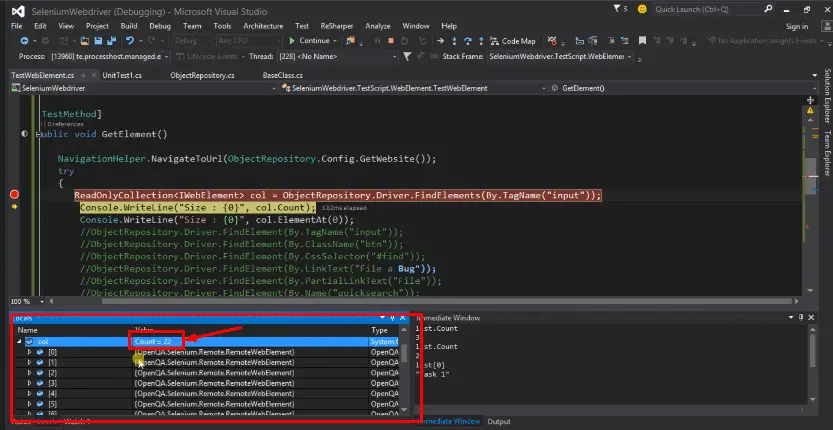
And the Count it is giving is 22 in immediate window. When we step over and want to retrieve the first element so it is also returning the details about it in immediate window.
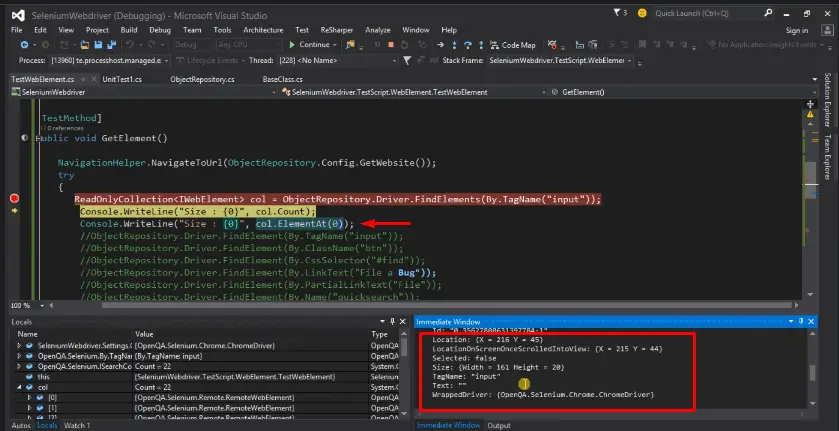
So that is the main difference between the FindElement() and FindElements(). FindElement() return the single web element based on the matching attribute and FindElements() return us the multiple elements in the form of ReadOnlyCollection that means in the form of list which cannot modify it is used only for the reading purpose.
That’s all for identifying the web elements on the webpage in Selenium C#, i hope you all have understand now.
