What is Software Testing Technique?
Software Testing Techniques help you design better test cases. Since exhaustive testing is not possible; Manual Testing Techniques help reduce the number of test cases to be executed while increasing test coverage. They help identify test conditions that are otherwise difficult to recognize. Five important Software Testing Techniques are:
- Boundary Value Analysis (BVA)
- Equivalence Class Partitioning
- Decision Table based testing.
- State Transition
- Error Guessing
Boundary Value Analysis (BVA)
BVA is another Black Box Test Design Technique, which is used to find the errors at boundaries of input domain (tests the behavior of a program at the input boundaries) rather than finding those errors in the center of input. So, the basic idea in boundary value testing is to select input variable values at their: minimum, just above the minimum, just below the minimum, a nominal value, just below the maximum, maximum and just above the maximum. That is, for each range, there are two boundaries, the lower boundary (start of the range) and the upper boundary (end of the range) and the boundaries are the beginning and end of each valid partition. We should design test cases which exercise the program functionality at the boundaries, and with values just inside and outside the boundaries. Boundary value analysis is also a part of stress and negative testing.
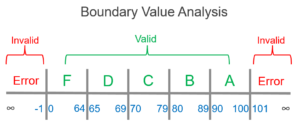
Test cases for input box accepting numbers between 1 and 1000 using Boundary value analysis:
- Test cases with test data exactly as the input boundaries of input domain i.e. values 1 and 1000 in our case.
- Test data with values just below the extreme edges of input domains i.e. values 0 and 999.
- Test data with values just above the extreme edges of the input domain i.e. values 2 and 1001.
Boundary Value Analysis is often called as a part of the Stress and Negative Testing
Equivalence Class Partitioning
Equivalence partitioning is also known as “Equivalence Class Partitioning”. In this method, the input domain data is divided into different equivalence data classes – which are generally termed as ‘Valid’ and ‘Invalid’. The inputs to the software or system are divided into groups that are expected to exhibit similar behavior. Thus, it reduces the number of test cases to a finite list of testable test cases covering maximum possibilities.
In equivalence-partitioning technique we need to test only one condition from each partition. This is because we are assuming that all the conditions in one partition will be treated in the same way by the software. If one condition in a partition works, we assume all of the conditions in that partition will work, and so there is little point in testing any of these others. Similarly, if one of the conditions in a partition does not work, then we assume that none of the conditions in that partition will work so again there is little point in testing any more in that partition.

Test cases for input box accepting numbers between 1 and 1000 using Equivalence Partitioning:
- One input data class with all valid inputs. Pick a single value from range 1 to 1000 as a valid test case. If you select other values between 1 and 1000 the result is going to be the same. So one test case for valid input data should be sufficient.
- Input data class with all values below the lower limit. I.e. any value below 1, as an invalid input data test case.
- Input data with any value greater than 1000 to represent the third invalid input class.
So using Equivalence Partitioning you have categorized all possible test cases into three classes. Test cases with other values from any class should give you the same result.
We have selected one representative from every input class to design our test cases. Test case values are selected in such a way that largest number of attributes of equivalence class can be exercised.
Equivalence Partitioning uses fewest test cases to cover maximum requirements.
Decision Table Based Testing
Decision table is a brief visual representation for specifying which actions to perform depending on given conditions. The information represented in decision tables can also be represented as decision trees or in a programming language using if-then-else and switch-case statements.
A decision table is a good way to settle with different combination inputs with their corresponding outputs and also called cause-effect table. Reason to call cause-effect table is a related logical diagramming technique called cause-effect graphing that is basically used to obtain the decision table.
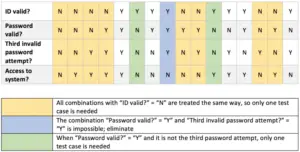
Importance of Decision Table
- Decision tables are very much helpful in test design techniques.
- It helps testers to search the effects of combinations of different inputs and other software states that must correctly implement business rules.
- It provides a regular way of stating complex business rules, that are helpful for developers as well as for testers.
- It assists in the development process with developers to do a better job. Testing with all combinations might be impractical.
- A decision table is basically an outstanding technique used in both testing and requirements management.
- It is a structured exercise to prepare requirements when dealing with complex business rules.
- It is also used in model complicated logic.
Advantages of Decision Table Testing
- Helps to identify all the important combinations of conditions. Otherwise, we may overlook.
- Identification of any gaps in the requirements is possible.
- It is useful at any test level where the software behavior depends on multiple combinations of conditions.
- Conversion of complex business rules into simple decision tables which the business users, testers, and developers may use.
Limitations
- The decision table test case design technique is challenging when there are no requirements or no well-designed requirements.
- The tables become more complex as the number of input values increases.
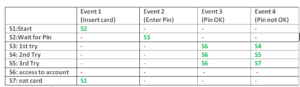
State Transition
State Transition testing, a black box testing technique, in which outputs are triggered by changes to the input conditions or changes to ‘state’ of the system. In other words, tests are designed to execute valid and invalid state transitions.
When to use?
- When we have a sequence of events that occur and associated conditions that apply to those events
- When the proper handling of a particular event depends on the events and conditions that have occurred in the past
- It is used for real-time systems with various states and transitions involved
Deriving Test cases
- Understand the various state and transition and mark each valid and invalid state
- Defining a sequence of an event that leads to an allowed test ending state
- Each one of those visited state and traversed transition should be noted down
- Steps 2 and 3 should be repeated until all states have been visited and all transitions traversed
- For test cases to have a good coverage, actual input values and the actual output values have to be generated
Advantages
- Allows testers to familiarize with the software design and enables them to design tests effectively.
- It also enables testers to cover the unplanned or invalid states.
Error Guessing
Error Guessing is a Software Testing technique on guessing the error which can prevail in the code.
It is an experience-based testing technique where the Test Analyst uses his/her experience to guess the problematic areas of the application. This technique necessarily requires skilled and experienced testers.
It is a type of Black-Box Testing technique and can be viewed as an unstructured approach to Software Testing.
For Example, if the Analyst guesses that the login page is error-prone, then the testers will write detailed test cases concentrating on the login page. Testers can think of a variety of combinations of data to test the login page.
To design test cases based on the Error Guessing technique, the Analyst can use past experiences to identify the conditions.
This technique can be used at any level of testing and for testing the common mistakes like
- Divide by zero
- Entering blank spaces in the text fields
- Pressing the submit button without entering values.
- Uploading files exceeding maximum limits.
- Null pointer exception.
- Invalid parameters
- The achievement rate of this technique does mainly depends upon the ability of testers.
Purpose Of Error Guessing In Software Testing
The main purpose of this technique is to guess possible bugs in the areas where formal testing would not work.
It should obtain an all-inclusive set of testing without any skipped areas, and without creating redundant tests.
This technique compensates for the characteristic incompleteness of Boundary Value Analysis and Equivalence Partitioning techniques.
Procedure For Error Guessing Technique
Error Guessing is fundamentally an intuitive and ad-hoc process; hence it is very difficult to give a well-defined procedure to this technique. The basic way is to first list all possible errors or error-prone areas in the application and then create test cases based on that list.
Error Guessing Example
Suppose there is a requirement stating that the mobile number should be numeric and not less than 10 characters. And, the software application has a mobile no. field.
Now, below are the Error Guessing technique:
- What will be the result if the mobile no. is left blank?
- What will be the result if any character other than a numeral is entered?
- What will be the result if less than 10 numerals are entered?
Advantages of Error Guessing technique
- Proves to be very effective when used in combination with other formal testing techniques.
- It uncovers those defects which would otherwise be not possible to find out, through formal testing. Thus, the experience of the tester saves a lot of time and effort.
- Error guessing supplements the formal test design techniques.
- Very helpful to guess problematic areas of the application.
Limitations
- The focal shortcoming of this technique is that it is person dependent and thus the experience of the tester controls the quality of test cases.
- It also cannot guarantee that the software has reached the expected quality benchmark.
- Only experienced testers can perform this testing. You can’t get it done by freshers.